分享主题
MSQL架构、索引介绍及原理
分享目标
- 理解MySQL架构组件及功能
- 理解MySQL执行流程
- 掌握MySQL中的表数据和索引在底层是如何被存储
- 掌握聚集索引(IOT索引组织表)和非聚集索引(堆组织表)的存储方式
- 掌握索引覆盖和回表概念
MySQL架构篇
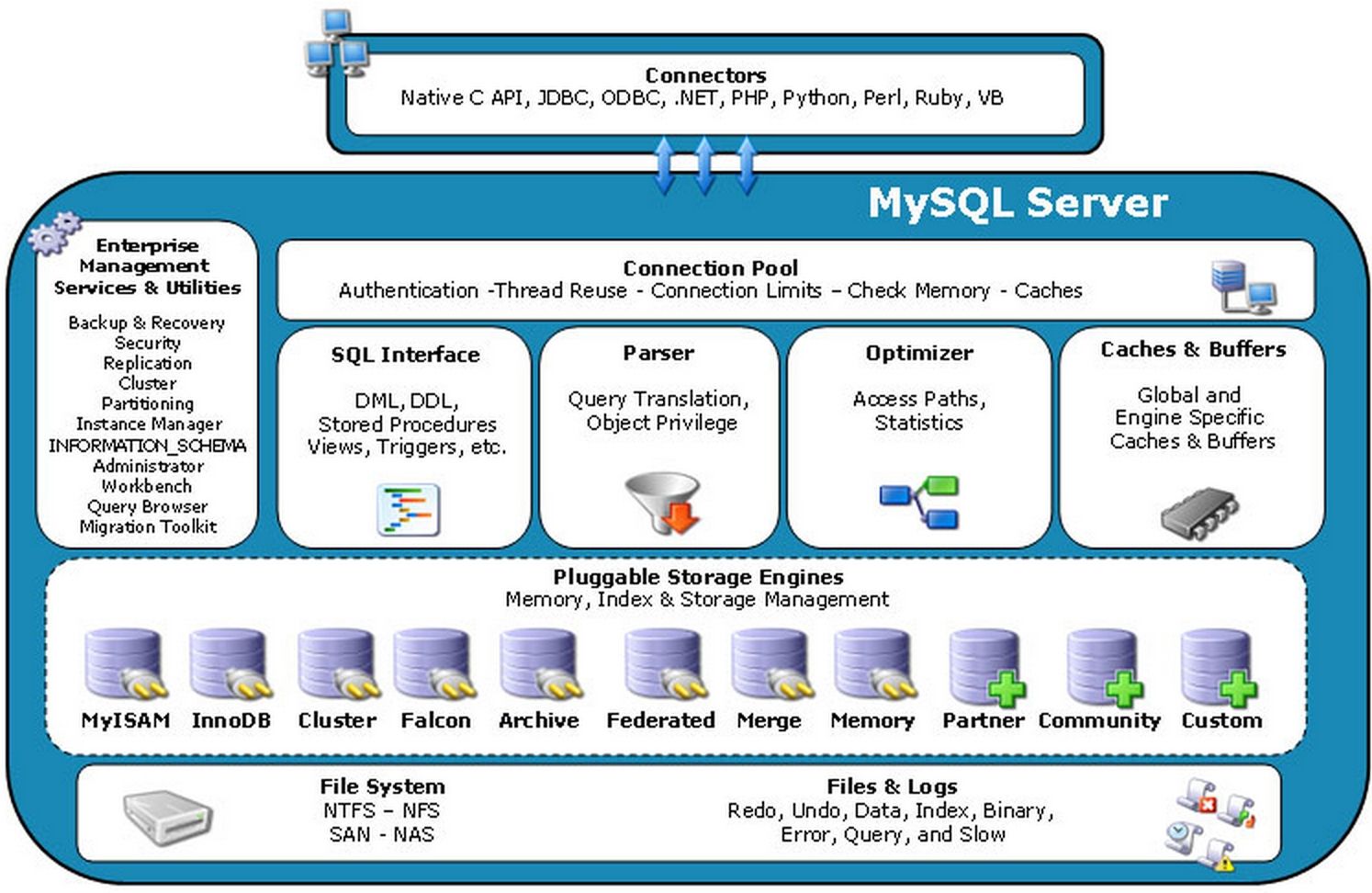
Connectors
连接器,指的是不同语言中与SQL的交互
Management Serveices & Utilities
系统管理和控制工具
Connection Pool: 连接池
- 管理缓冲用户连接,线程处理等需要缓存的需求。
- 负责监听对 MySQL Server 的各种请求,接收连接请求,转发所有连接请求到线程管理模块。每一个连接上MySQL Server 的客户端请求都会被分配(或创建)一个连接线程为其单独服务。
- 而连接线程的主要工作就是负责 MySQL Server 与客户端的通信,接受客户端的命令请求,传递 Server 端的结果信息等。线程管理模块则负责管理维护这些连接线程。包括线程的创建,线程的 cache 等。
SQL Interface: SQL接口
接受用户的SQL命令,并且返回用户需要查询的结果。比如select from就是调用SQL Interface
Parser: 解析器
SQL命令传递到解析器的时候会被解析器验证和解析。
主要功能:
- 将SQL语句进行语义和语法的分析,分解成数据结构,然后按照不同的操作类型进行分类,然后做出针对性的转发到后续步骤,SQL语句的传递和处理就是基于这个结构的。
- 如果在分解过程中遇到错误,那么就说明这个sql语句是不合理的。
Optimizer: 查询优化器
SQL语句在查询之前会使用查询优化器对查询进行优化。explain语句查看的SQL语句执行计划,就是由查询优化器生成的。
Cache和Buffer: 查询缓存
他的主要功能是将客户端提交给MySQL的 select请求的返回结果集 cache 到内存中,与该 query 的一个 hash 值 做一个对应。该 Query 所取数据的基表发生任何数据的变化之后, MySQL 会自动使该 query 的Cache 失效。在读写比例非常高的应用系统中, Query Cache 对性能的提高是非常显著的。当然它对内存的消耗也是非常大的。
如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。这个缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,key缓存,权限缓存等
Pluggable Storage Engines:存储引擎
与其他数据库例如Oracle 和SQL Server等数据库中只有一种存储引擎不同的是,MySQL有一个被称为“PluggableStorage Engine Architecture”(可插拔的存储引擎架构)的特性,也就意味着MySQL数据库提供了多种存储引擎。
而且存储引擎是针对表的,用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎。也就是说,同一数据库不同的表可以选择不同的存储引擎
存储引擎介绍
- MySQL存储引擎类型
| 存储引擎 | 说明 |
|---|---|
| MyISAM | 高速引擎,拥有较高的插入,查询速度,但不支持事务 |
| InnoDB | 5.5版本后MySQL的默认数据库,支持事务、行级锁、表级锁,比MyISAM处理速度稍慢 |
| ISAM | MyISAM的前身,MySQL5.0以后不再默认安装 |
| MRG_MyISAM(MERGE) | 将多个表联合成一个表使用,在超大规模数据存储时很有用 |
| Memory | 内存存储引擎,拥有极高的插入,更新和查询效率。但是会占用和数据量成正比的内存空间。只在内存上保存数据,意味着数据可能会丢失 |
| Falcon | 一种新的存储引擎,支持事务处理,传言可能是innoDB的替代者 |
| Archive | 将数据压缩后进行存储,非常适合存储大量的独立的历史记录数据,但是只能进行插入和查询操作 |
| CSV | CSV存储引擎是基于CSV格式文件存储数据(应用于跨平台的数据交换) |
- MyISAM和InnoDB存储引擎的区别
| InnoDB | MyISAM | |
|---|---|---|
| 存储文件 | .frm 表定义文件 .ibd 数据文件和索引文件 |
.frm 表定义文件 .MYD 数据文件 .MYI 索引文件 |
| 存储限制 | 64TB | 无 |
| 锁 | 行锁、表锁 | 表锁 |
| 事务 | 支持 | 不支持 |
| CRUD | 读、写 | 读 |
| count | 扫表 | 专门存储的地方 |
| 支持外键 | 支持 | 不支持 |
| 索引结构 | B+ Tree | B+ Tree |
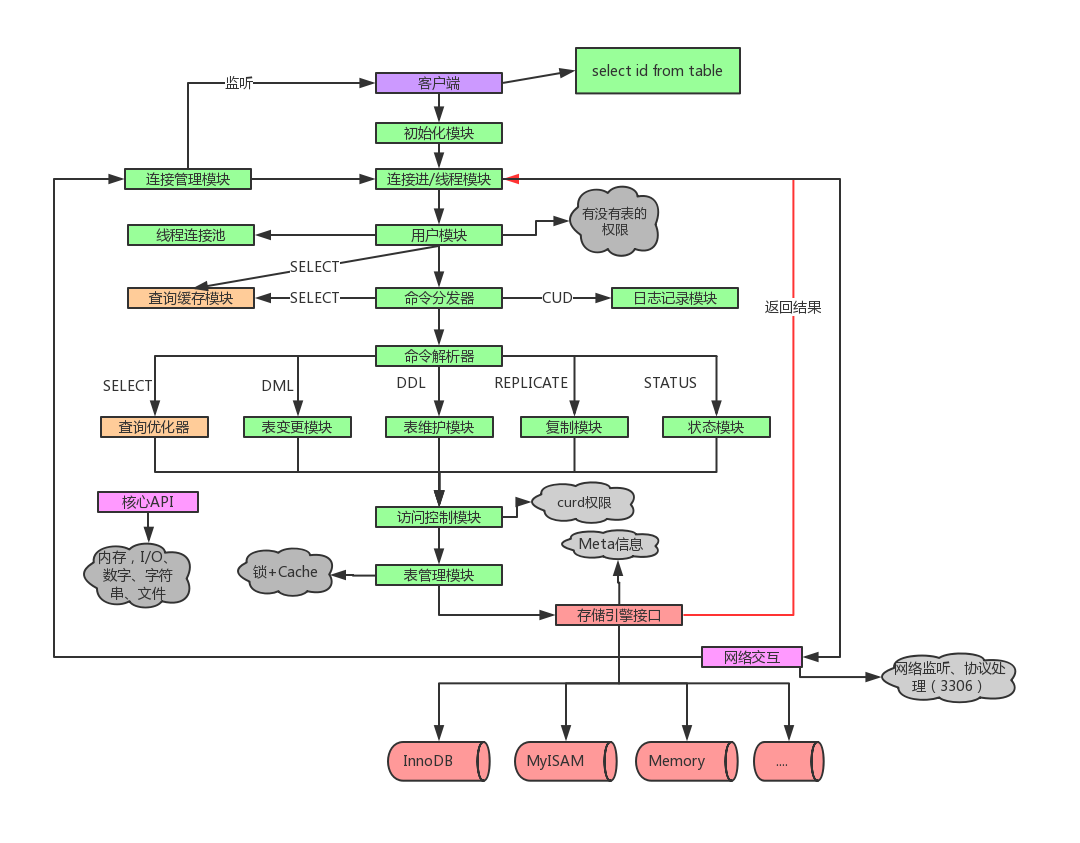
简版执行流程图
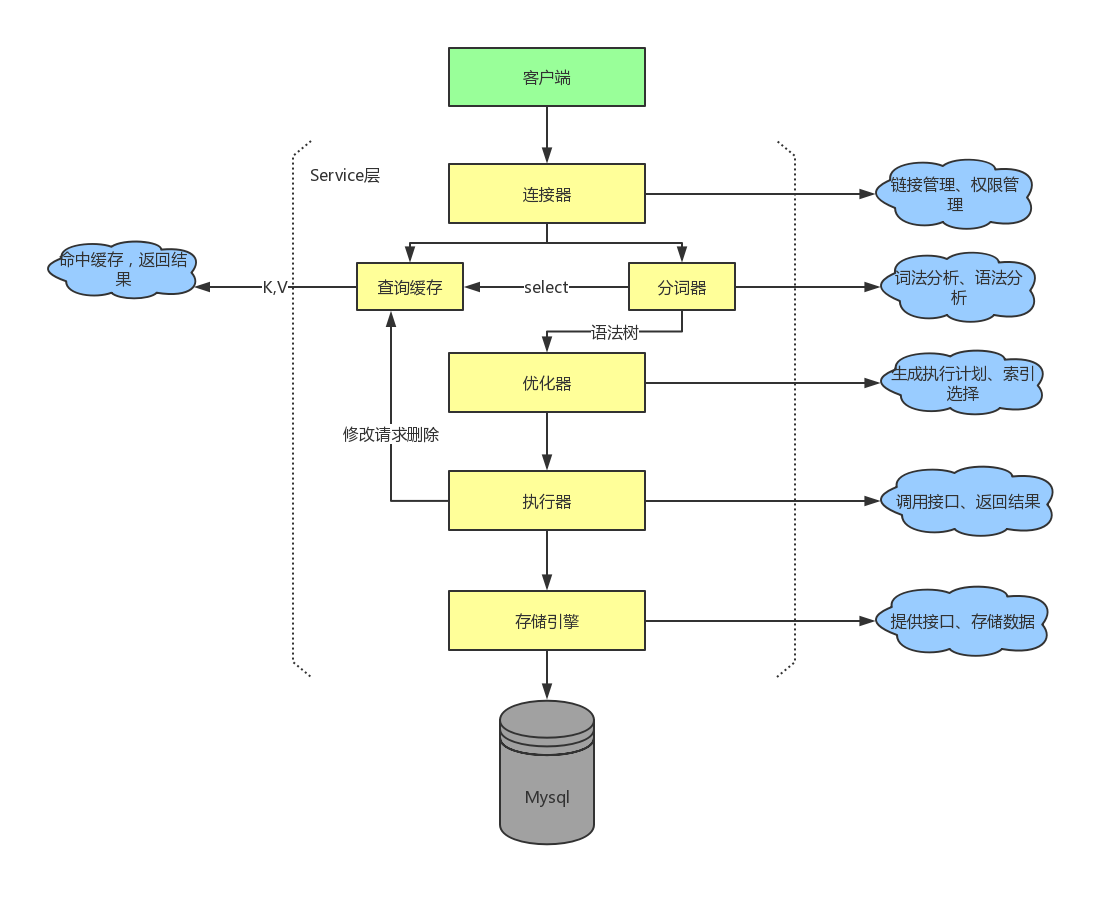
详细执行流程图
物理文件
日志文件(顺序IO)
MySQL通过日志记录了数据库操作信息和错误信息。常用的日志文件包括错误日志、二进制日志、查询日志、慢查询日志、事务Redo日志、中继日志等。
错误日志(errorlog)
默认是开启的,而且从5.5.7以后无法关闭错误日志,错误日志记录了运行过程中遇到的所有严重的错误信息,以及MySQL每次启动和关闭的详细信息。
二进制日志(bin log)
默认是关闭的,binlog记录了数据库所有的ddl语句和dml语句,但不包括select语句内容,语句以时间的形式保存,描述了数据的变更顺序,binlog还包括了每个更新语句的执行时间信息。如果是DDL语句,则直接记录到binlog日志,而DML语句,必须通过事务提交才能记录到binlog日志中。
binlog主要用户实现mysql主从复制、数据备份、数据恢复、数据监听。
通用查询日志(general query log)
默认情况下通用查询日志是关闭的。查询日志记录客户端的所有语句(所有连接和语句都记录到通用日志)。
慢查询日志(slow query log)
慢查询日志记录了所有执行时间超过参数long_query_time设置值并且扫描记录数不小于min_examined_row_limit的所有SQL语句的日志(获得表锁定的时间不能算作执行时间)。
show_query_log:参数设置为ON,可以捕获执行时间超过一定数值的SQL语句。
long_query_time:默认是10秒,最小为0,精度可以到微妙
min_examined_row_limit:查询检查返回少于该参数指定行的SQL不被记录到慢查询日志
重做日志(redo log)
- 确保事务的持久性。
- 防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。
回滚日志(undo log)
保存了事务发生之前数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),即非锁定读。
中继日志(relay log)
- 是在主从复制环境中产生的日志。
- 主要作用是为了从机可以从中继日志中获取到主机同步过来的SQL语句,然后执行到从机中。
数据文件(随机IO)
InnoDB数据文件
- .frm文件:主要存放于表相关的数据信息,主要包括表结构的定义信息。
- .ibd文件:使用独享表空间存储表数据和索引信息,一张表对应一个ibd文件。
- ibdata文件:使用共享表空间存储表数据、索引和缓存信息,所有表共同使用一个或者多个ibdata文件。
MyISAM数据文件
- .frm文件:主要存放于表相关的数据信息,主要包括表结构的定义信息。
- .myd文件:主要用来存储表数据信息。
- .myi文件:主要用来存储表数据文件中任何索引的数据树。
MySQL性能分析
- 通过观察查询慢日志,确定具体哪些SQL比较慢(功能默认是关闭,需要手动开启)
- 通过explain和慢SQL分析
- 通过show profile查看慢SQL执行的性能情况,包括CPU、IO、执行SQL锁消耗的时间等。该工具在5.0.37以及以上版本中才能使用(功能默认是关闭,需要手动开启)
MySQL索引
索引是什么
- 索引可以大大提高MySQL的检索速度
- 使用B+树结构(多路搜索树,并不一定是二叉)
- 索引是存储在磁盘文件中的(可能在单独的索引文件,也可能和数据存在一起)
索引的优势和劣势
优点
- 索引大大减少了服务器需要扫描的数据量
- 索引可以帮助服务器避免排序的临时表
- 索引可以将随机I/O变成顺序IO
缺点
- 索引需要占用磁盘空间
- 索引在更新表时会降低效率,新增、修改、删除
哪些情况需要创建索引
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 多表关联查询中,关联字段应该创建索引 on 两边都要创建索引
- 查询中排序的字段,应该创建索引
- 频繁查找字段 覆盖索引
- 查询中统计或者分组字段,应该创建索引 group by
哪些情况不需要创建索引
- 表记录太少
- 经常进行增删改操作的表
- 频繁更新的字段
- where条件里使用频率不高的字段
为什么使用组合索引
mysql创建组合索引的规则是首先会对组合索引的最左边的,也就是第一个a字段的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个的b字段进行排序。其实就相当于实现了类似 order by a b这样一种排序规则。
为了节省mysql索引存储空间以及提升搜索性能,可建立组合索引(能使用组合索引就不使用单列索引)
例如:
创建组合索引(相当于建立了col1,col1 col2,col1 col2 col3三个索引):
1 | ALTER TABLE 'table_name' ADD INDEX index_name('col1','col2','col3') |
常用索引分类
单列索引
普通索引
- 这是最基本的索引,它没有任何限制
唯一索引
- 这种索引和普通索引基本相同,但有一个区别:索引列的所有值都只能出现一次,即必须唯一,允许为空
- 主键索引(PRIMARY KEY)是一种特殊的唯一索引,创建类型推荐使用int类型
- 建表时未设置主键索引,mysql会默认新建6byte空间的自动增长主键,可以用select _rowid from table来查询
组合索引
- 在表中的多个字段组合成一个索引
- 建议使用组合索引代替单列索引
- 组合索引需要遵循最左原则
索引存储结构
索引存储结构介绍
- 索引是在存储引擎中实现的。
- MyISAM和InnoDB存储引擎:只支持BTREE索引,也就是默认使用BTREE,不能修改
B树和B+树
数据结构示例网站:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
B树示图
- B树是为了磁盘或其它存储设备而设计的一种多叉(下面你会看到,相对于二叉,B树每个内结点有多个分支,即多叉)平衡查找树。 多叉平衡
- B树的高度一般都是在2-4这个高度,树的高度直接影响IO读写的次数,以及查询时间复杂度(log(n))
- 如果是三层树结构—支撑的数据可以达到20G,如果是四层树结构—支撑的数据可以达到几十T
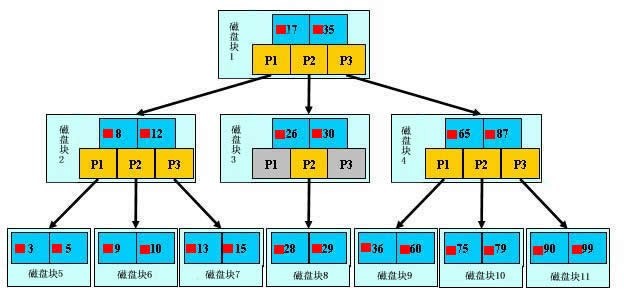
B+树示图
B树和B+树的区别
B树和B+树的最大区别在于非叶子节点是否存储数据的问题。
1 | - B树是非叶子节点和叶子节点都会存储数据,存放数据地址 |
非聚集索引(MyISAM)
- B+树叶子节点只会存储数据行(数据文件)的指针,简单来说数据和索引不在一起,就是非聚集索引。
- 非聚集索引包含主键索引和辅助索引都会存储指针的值
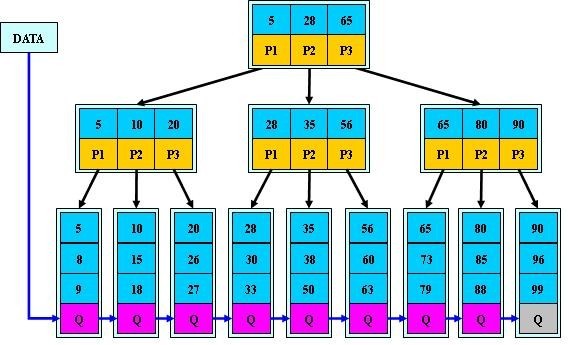
主键索引
这里设表一共有三列,假设我们以 Col1 为主键,则上图是一个 MyISAM 表的主索引(Primary key)示意。可以看出
MyISAM 的索引文件仅仅保存数据记录的地址。
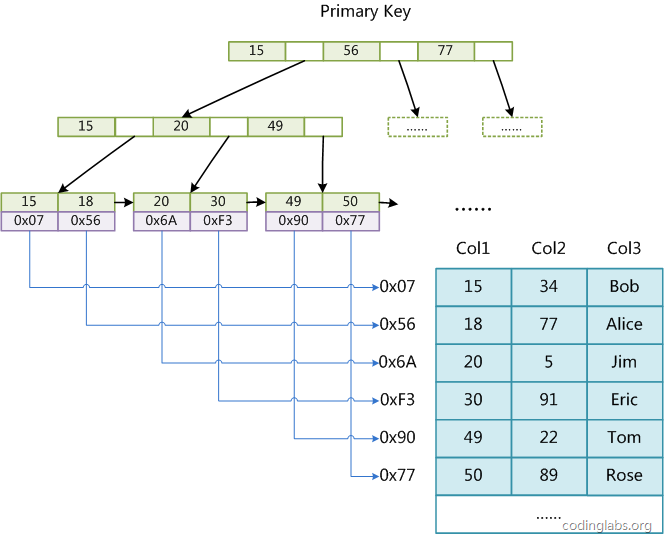
辅助索引(次要索引)
在 MyISAM 中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求 key 是唯一的,而辅助索引的 key 可以重复。如果我们在 Col2 上建立一个辅助索引,则此索引的结构如下图所示
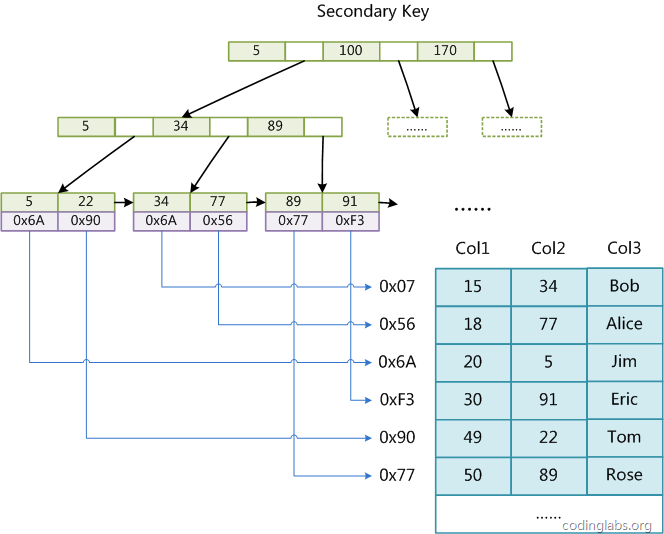
聚集索引(InnoDB)
- 主键索引(聚集索引)的叶子节点会存储数据行,也就是说数据和索引是在一起,这就是聚集索引
- 辅助索引只会存储主键值
- 如果没有没有主键,则使用唯一索引建立聚集索引;如果没有唯一索引,MySQL会按照一定规则创建聚集索
引
主键索引
- InnoDB 要求表必须有主键(MyISAM 可以没有),如果没有显式指定,则 MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL 自动为 InnoDB 表生成一个隐含字段作为主键,类型为长整形。
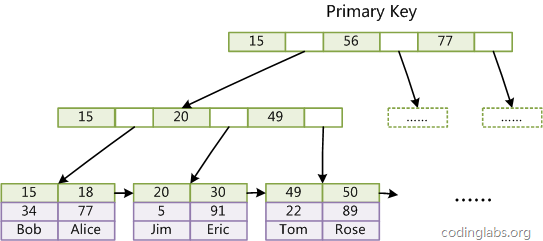
- 上图是 InnoDB 主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为 InnoDB 的数据文件本身要按主键聚集,
辅助索引(次要索引)
第二个与 MyISAM 索引的不同是 InnoDB 的辅助索引 data 域存储相应记录主键的值而不是地址。换句话
说,InnoDB 的所有辅助索引都引用主键作为 data 域。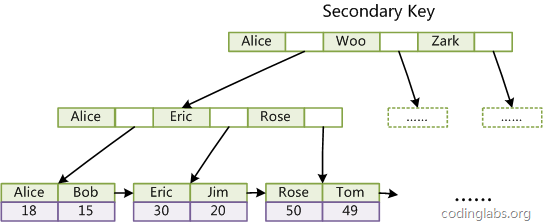
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
1 | select * from user where name='Alice' ##回表 |
索引覆盖与回表查询
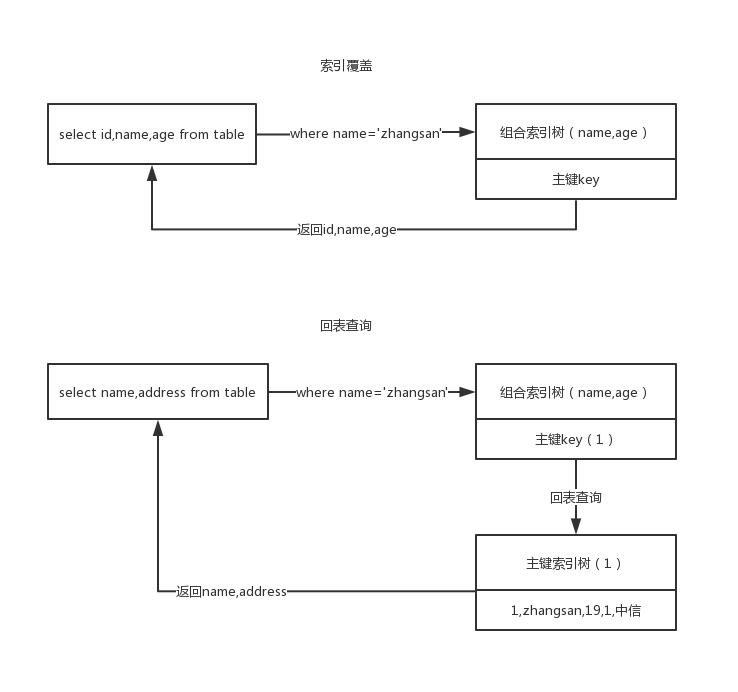
- 索引覆盖是指返回的列在针对辅助索引树上都存在,name,age形成组合索引,查询返回的列id,name,age都在索引树上,不需要再次回表查询主键索引树就能返回查询数据
- 回表是指查询条件非主键索引,通过辅助索引去查询数据,无法在辅助索引列上一次获取到所有需要的列字段,通过辅助索引查询获取到值(主键索引ID)再去查询主键索引树来获取返回列数据
【参考链接】

